This is a guest blog by Octavi Gómez-Novell, Universitat de Barcelona, visiting researcher at Universidad Complutense de Madrid (Spain). Contact: octgomez@ub.edu
Paleoseismic data are punctual and highly localized in defined fault strands, while earthquake surface ruptures cover much larger and complex regions in comparison. This makes the identification of paleoearthquakes in trenches strongly dependent on the slip that those particular events had at each trench site, as well as on the continuity and quality of the stratigraphy for those paleoearthquakes to be dated and well-constrained in time. For this reason, paleoseismologists always seek to increase observations by trenching several sites along fault deformation zones with the premise that more observational data might: 1) complete the paleoearthquake catalogues closer to the real event count that actually occurred, 2) reduce the event age and detection uncertainties and 3) give insight about surface rupture characteristics. While all of these premises are correct and proven successful in several cases, the truth is that in a handful of other cases increasing observations can significantly difficult the correlation of datasets between sites, making such interpretations highly subjective. For instance, in very populated paleoseismic datasets and/or those with large event date uncertainties there will be multiple correlation options; which is the right one? After all, even though based on observations, paleoseismic data are interpretations, hence models that should be treated as such. Thus, can we improve correlation using numerical modelling?
Numerical modelling for paleoseismic correlation
The focus of the paleoseismology community in this topic is not as prevalent as one might think, with only a couple of studies in the Wasatch Fault in the United States (DuRoss et al., 2011) and the Central Apennines in Italy (Cinti et al. 2021) developing modelling approaches to solve paleoearthquake correlations. However, one question remained: what if paleoseismic data in two sites highly overlap in time? Take the example in figure 1. Event S1 in site 1 overlaps events R1 and R2 in site 2. This means that S1 could be R1, R2, both of them or none of them. Which is the right call? In reality we cannot rule out any of the correlation possibilities because paleoseismic observations are always a minimum.
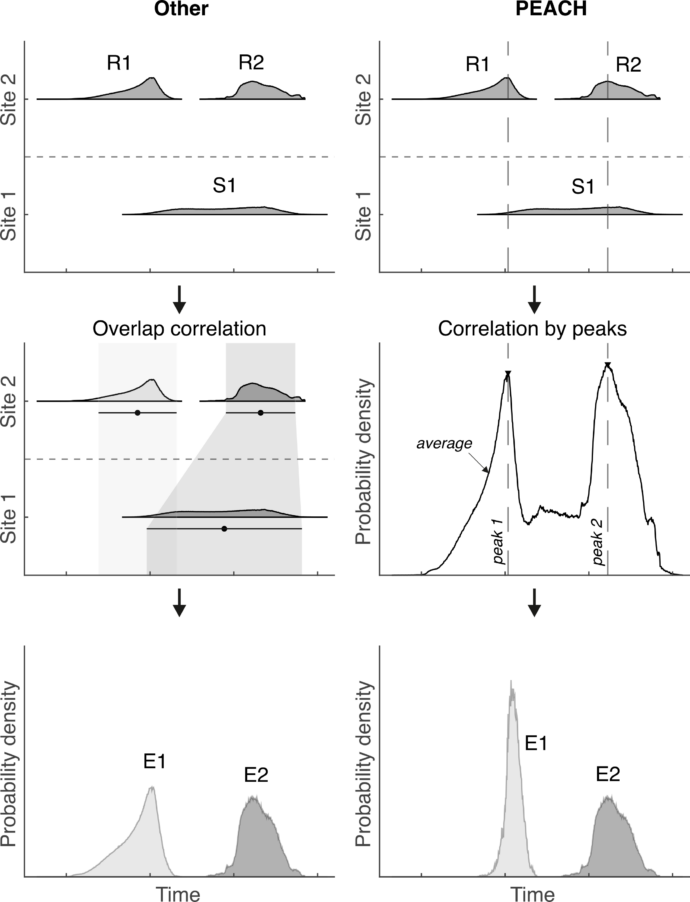
The PEACH tool
PEACH is an approach written on a MATLAB algorithm and available at https://doi.org/10.5281/zenodo.8434566 designed to automatically derive entire fault chronologies from the correlation of paleoearthquake datasets from multiple sites along a fault. The approach works with numerical dates defining stratigraphic event horizons as inputs and employs a probabilistic modelling to derive the paleoearthquake dates. To do so the algorithm follows an automatic process to 1) build the paleoearthquake probability density functions (PDFs), 2) compute the average probability distribution of the whole dataset, 3) detect the probability peaks and 4) compute the overall fault chronology by multiplying all site PDFs intersecting the peak locations (Fig. 1). This approach allows unrestricted correlation between PDF pairs, meaning that one event can participate in more than one correlation if its time span overlaps with several other events. Such a feature allows to numerically accommodate the detectability uncertainties intrinsic to paleoseismic data (e.g., one event potentially being more than one; see example in figure 1). PEACH is easy to use with simple and straightforward inputs and can also work with pre-computed OxCal (Bronk Ramsey, 2009) chronologies if preferred. This OxCal module might be useful in the cases where the individual events in a site should have skewed PDFs based on stratigraphic age criteria such as colluvial wedges; an imposed condition that can be modelled with OxCal (e.g., DuRoss et al., 2011). The resulting output PEACH chronologies are stored as simple text-based files that can be further used to calculate fault parameters such as earthquake recurrence interval and recurrence model by means of the coefficient of variation. Moreover, each code run generates plots of the modelled chronologies so their quality can be checked, and they can be easily used for publications or reports.
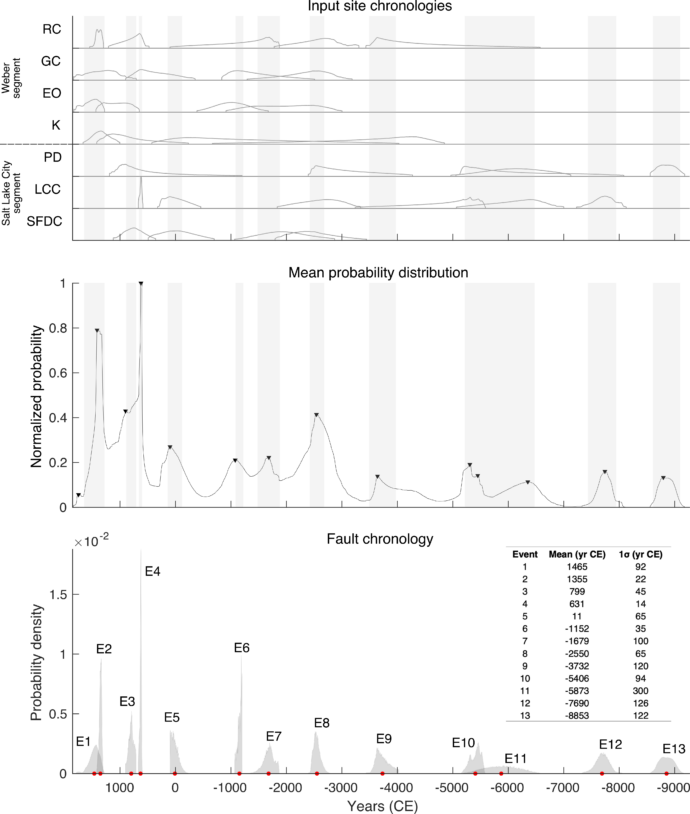
Applicability
Here we show one application of PEACH on two of the central segments of the Wasatch Fault in the United States: the Weber and the Salt Lake City segments. We correlate the published OxCal chronologies compiled in DuRoss et al. (2016) for 7 different paleoseismic sites. As you can see in figure 2, the OxCal input chronologies in each site are quite well constrained but deriving a chronology can be quite difficult manually. PEACH computes a final chronology for both segments combined based on the mean probability distribution of all event PDFs. This yields a reasonably well-constrained final chronology of 13 events that completes the event count that would be derived from the initial individual site chronologies only. Take a look at how the skewness on the OxCal event PDFs – coming from imposed stratigraphic conditions by the original authors – allows refining allows refining the chronologies in some cases (e.g., events E6 and E7 in figure 2).
Another potentiality of PEACH, although not intrinsic to the design of the tool, is that it can be used to infer or, at least, discuss the possible spatial extent of the fault ruptures. From the final chronology we can see from which sites that event has been derived (e.g., we could filter by selecting only those events that contribute with higher probability). Then, using the geo-spatial position of each site along fault, one can visually have an idea of the sites where that event likely ruptured. This can be useful to analyze whether ruptures have likely jumped across known segment boundaries or not. Having said that, we clarify that this type of exercise is not part of PEACH and therefore is not implemented computationally in it; we advise that interpretations should be made cautiously in this regard. Bear in mind that, after all, it is the user the one who ultimately selects which sites are going to be correlated.
Future work
We hope that PEACH becomes a useful tool for those researchers seeking to do a robust analysis of their paleoseismic datasets. The tool could help them gain clarity and resolution in the data (especially when datasets are large or complicated), compute parameters on fault recurrence and do observations that might give insight on fault rupture extent and behavior.
We are committed on keeping PEACH updated and future releases are planned. Particularly, we expect to implement a module within PEACH to automatically derive potential rupture lengths from the correlation data. Also, we are currently translating the code to Python language.
Last but not least, we invite everyone to reach out to us with doubts, suggestions, or even potential collaborations. We hope you enjoy it!
Where to find PEACH
The methodological framework of PEACH is published in Geoscientific Model Development by Octavi Gómez Novell, Bruno Pace, Francesco Visini, Joanna Faure Walker and Oona Scotti at https://gmd.copernicus.org/articles/16/7339/2023/.
The PEACH code and user manual are available and ready to download at https://zenodo.org/records/8434566.
References
- Bronk Ramsey, C.: Bayesian Analysis of Radiocarbon Dates, Radiocarbon, 51, 337–360, https://doi.org/10.1017/S0033822200033865, 2009.
- Cinti, F. R., Pantosti, D., Lombardi, A. M., and Civico, R.: Modeling of earthquake chronology from paleoseismic data: Insights for regional earthquake recurrence and earthquake storms in the Central Apennines, Tectonophysics, 816, 229016, https://doi.org/10.1016/j.tecto.2021.229016, 2021.
- DuRoss, C. B., Personius, S. F., Crone, A. J., Olig, S. S., Hylland, M. D., Lund, W. R., and Schwartz, D. P.: Fault segmentation: New concepts from the Wasatch Fault Zone, Utah, USA, J. Geophys. Res.-Sol. Ea., 121, 1131–1157, https://doi.org/10.1002/2015JB012519, 2016.
- DuRoss, C. B., Personius, S. F., Crone, A. J., Olig, S. S., and Lund, W. R.: Integration of paleoseismic data from multiple sites to develop an objective earthquake chronology: Application to the Weber segment of the Wasatch fault zone, Utah, Bull. Seismol. Soc. Am., 101, 2765–2781, https://doi.org/10.1785/0120110102, 2011.
- Gómez-Novell, O., Pace, B., Visini, F., Faure Walker, J., and Scotti, O.: Deciphering past earthquakes from the probabilistic modeling of paleoseismic records – the Paleoseismic EArthquake CHronologies code (PEACH, version 1), Geosci. Model Dev., 16, 7339–7355, https://doi.org/10.5194/gmd-16-7339-2023, 2023.


{kind=link}
No Comments
No comments yet.